Every Interface You Need
A full desktop GUI with 10 pages, a 9-tab terminal TUI, and 21 CLI commands. All backed by the same Rust SDK.
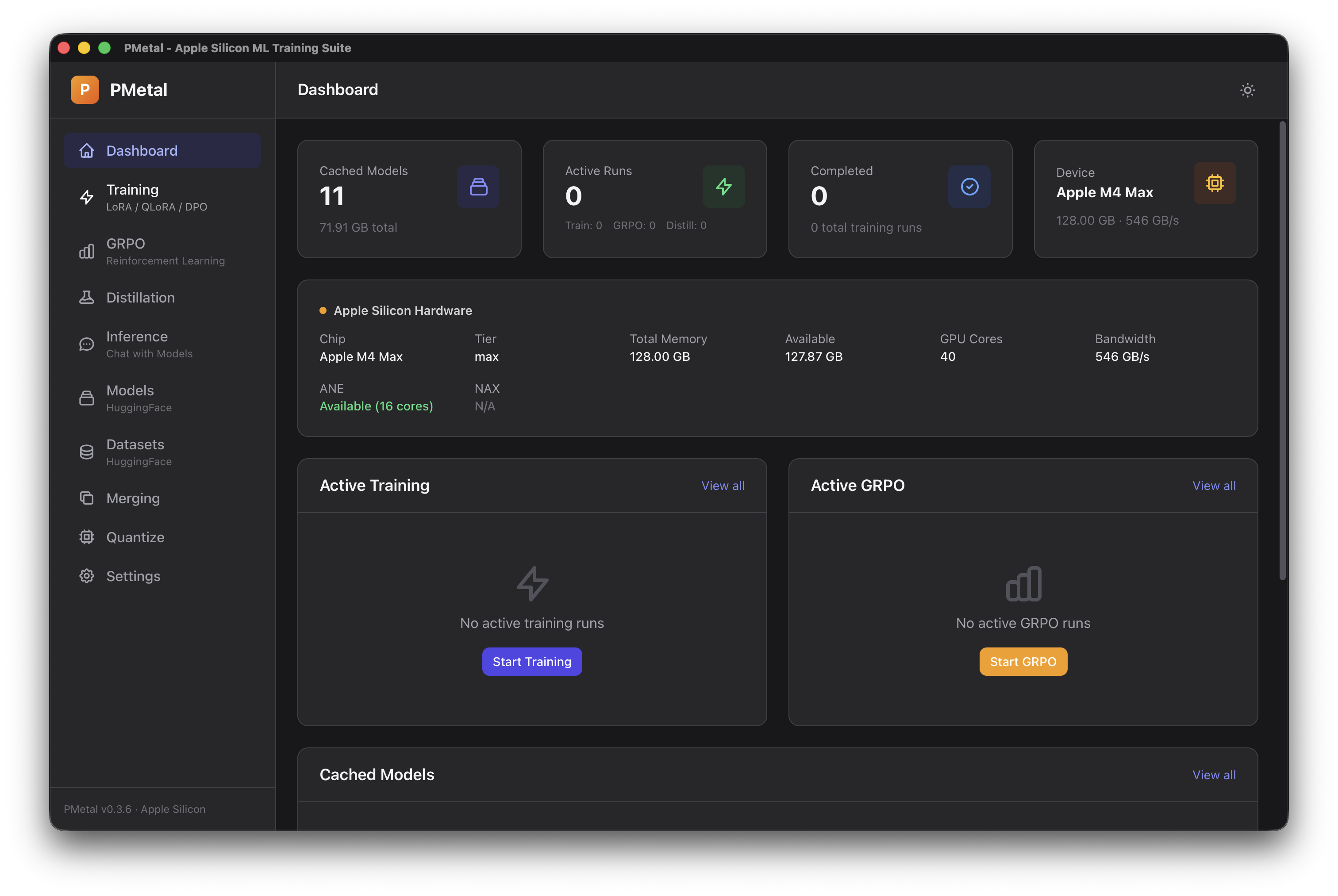
Desktop GUI — Tauri + Svelte with 10 pages for training, inference, merging, and quantization.
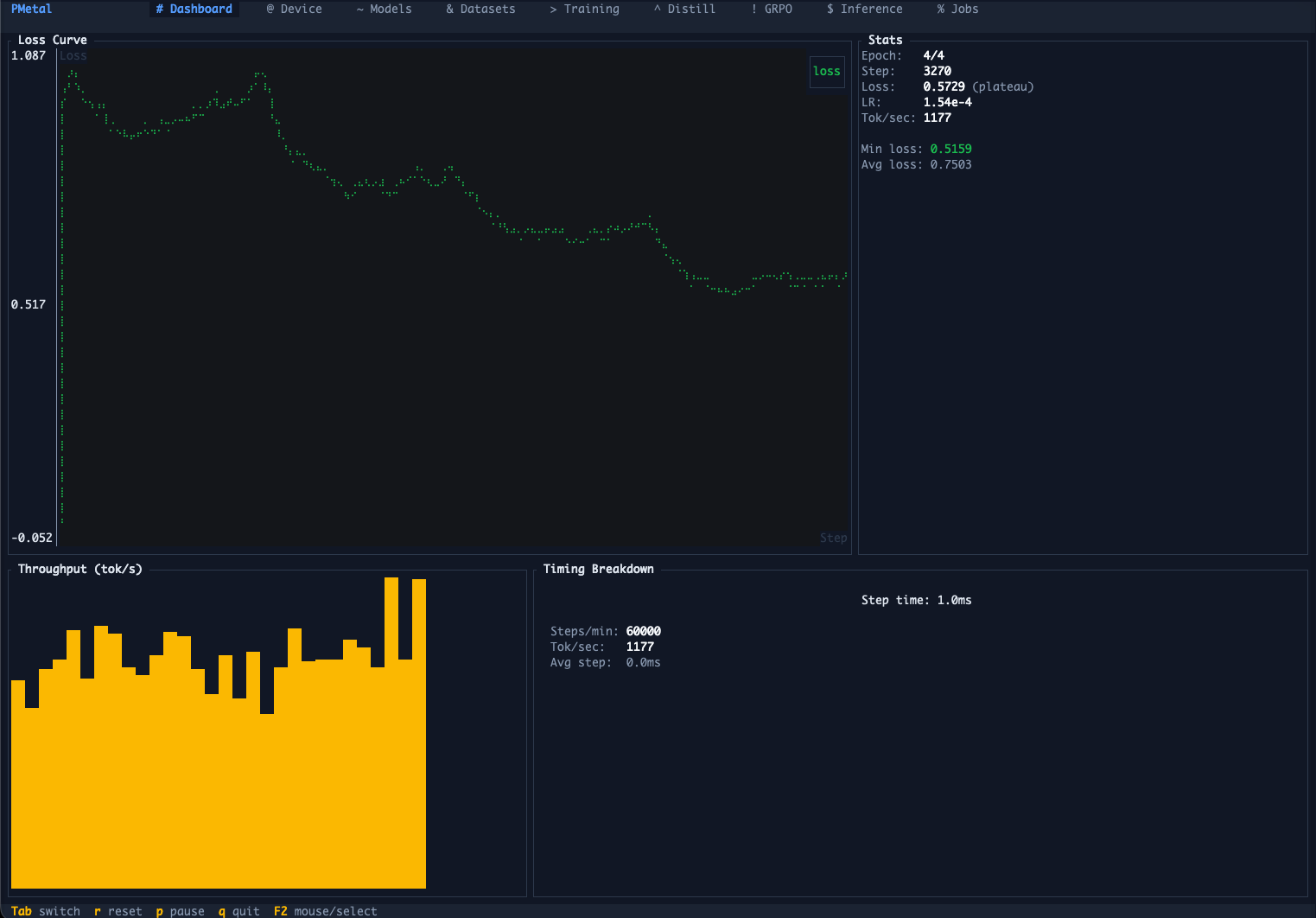
Terminal TUI — 9 tabs with live loss curves, device info, model search, and interactive chat.